Metal是我个人独立开发的一个项目,目前已经达成了演示版本的目标。不过仍然有些许问题要解决。本项目后续也将开放源代码。
What is Metal?
Metal是一款数据流建模软件,通过Metal可以管理数据流处理算子、可视化建模、批处理任务执行。
What Metal can do for you?
如果你经常使用Spark SQL开发ETL Pipeline,积累了大量的DTD(Dataframe To Dataframe)的算子/操作,你可以按照Metal的插件规范改造你的算子/操作,使用Metal来管理这些插件。
如果你使用Metal,你可以很方便地复用这些插件。Metal提供了两种方式来构建数据流,数据流是由插件组合而成的。
- 第一种构建方式是Cli风格,你需要编写spec文件来配置数据流的结构以及数据处理算子的参数。
- 第二方式是可视化风格,Metal提供了用于数据流设计的Web UI即metal-ui。metal-ui是一个简易的数据流集成开发环境,相比于Cli风格,metal-ui降低了配置数据流的难度。metal-ui以Project的概念管理每个数据流。你可以在metal-ui中,创建Project、配置Project、绘制数据流、跟踪数据处理任务、管理算子插件等。
Quick Start
为了快速体验Metal,你可通过以下安装方式建立一个测试体验环境。
预先准备
- OpenJDK 11及以上版本。
- npm 9.5.0及以上版本。
- Docker
- docker-compose
- maven
- mongodb tools
编译打包
在Metal项目根目录下,执行如下命令完成编译打包。
1
mvn package -Dmaven.test.skip=true
打包出的内容保存在./build目录下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
./build/
├── conf
│ ├── backend
│ │ ├── META-INF
│ │ ├── log4j.properties
│ │ └── zookeeper.json
│ ├── conf
│ │ └── metal-server.json
│ ├── log4j.properties
│ ├── metal-server.openapi.json
│ └── zookeeper.json
├── libs
│ ├── metal-backend-{VERSION}.jar
│ └── metal-server-{VERSION}.jar
├── sbin
│ └── db
│ ├── execs.json
│ ├── metals.json
│ ├── project.json
│ └── user.json
└── ui
└── webroot
├── asset-manifest.json
├── favicon.ico
├── images
├── index.html
├── logo192.png
├── logo512.png
├── manifest.json
├── robots.txt
└── static
准备运行依赖环境
启动服务
进入项目根目录下的./metal-test/docker目录,通过如下命令启动相关依赖服务(包括MongoDB、MongoDB Express、Zookeeper、Spark Standalone集群和HDFS)
1
docker-compose up -d
当然如果你不打算执行任何任务,只是想体验一下Metal的效果,你可以只启动MongoDB和Zookeeper。执行如下命令即可。
1
docker-compose up -d mongo zoo0
初始化MongoDB
首先,你需要在MongoDB中为Metal创建一个单独的数据库和用户。比如创建用户名为metal的用户和metalDB数据库,你可以在mongosh中执行如下命令,
1
2
3
4
5
6
use metalDB
db.createUser({
user: 'metal',
pwd: '123456',
roles: [{role: 'root', db: 'admin'}]
})
体验环境中的MongoDB的root用户密码为123456,地址为192.168.42.50,端口为27017。
接下来,你需要将构建目录下的db脚本导入到数据库。执行如下命令即可,
1
ls ../../build/sbin/db | awk -F '.' '{print $1}' | xargs -I {} mongoimport -c {} --type json --file ../../build/sbin/db/{}.json mongodb://<credentials>@<host>:<port>/metalDB
配置
项目在编译打包后,会将相关配置文件复制到$METAL/build/conf目录下。如果你使用了自定义的MongoDB和Zookeeper,你需要修改相关配置文件,否则跳过该部分。
- MongoDB:
$METAL/build/conf/conf/metal-server.json的如下几项需要修改为你提供的服务配置。1 2 3 4 5 6 7
{ ... "mongoConf": { "connection_string": "mongodb://<credentials>@<host>:<port>/<CUSTOM_DB>" }, ... }
- Zookeeper:
$METAL/build/conf/zookeeper.json的如下几项需要修改为你提供的服务配置。1 2 3 4 5
{ ... "zookeeperHosts": "<ZOOKEEPER_HOST>", ... }
启动Metal
在项目根目录下,执行如下命令完成启动。
1
java -cp ./build/libs/metal-server-{VERSION}.jar:./build/ui:./build/conf org.metal.server.GatewayLauncher
最后打开浏览器,链接http://localhost:19000即可。
测试用户名jack,密码123456。
Features
- 支持Spark SQL批处理引擎
- 处理算子复用和管理
- 支持
spark-submit命令行提交 - 提供了REST-API服务
- 支持可视化构建数据流
- 支持算子扩展
- 提供了打包工具
- 提供了Web-UI
- 支持用户级、Project级资源隔离
Architecture

Metal项目目前包括如下几个组件,
1
2
3
4
5
6
7
8
9
10
11
.
├── metal-backend
├── metal-backend-api
├── metal-core
├── metal-maven-plugin
├── metal-on-spark
├── metal-on-spark-extensions
├── metal-parent
├── metal-server
├── metal-test
└── metal-ui
各个组件概况如下:
metal-core
metal-core是Metal的核心,它定义了Metal数据流处理算子类型、数据流分析检查以及执行。
数据流处理算子
类型
Metal数据流处理算子包括四种,分别为Source、Mapper、Fusion和Sink。

从上图可以看出,所有算子/操作的最终父类为Metal,所有继承Metal的子类都有id、name以及配置属性props。其中,props用于为算子注入配置。metal-core下的Metal抽象算子是平台无关的。目前,Metal仅支持将Spark作为后端执行引擎。
上图中MSource、MMapper、MFusion和MSink定义了数据流的四种基本处理逻辑。
MSource: 用于获取数据,没有数据输入,有输出。例如JsonFileSource是MSource在Spark上的一种实现。JsonFileSource用从文件中加载JSON格式的数据,返回一个带有模式的DataFrame。MMapper:用于处理数据,拥有一个输入,并且有输出。例如SqlMMapper是MMapper在Spark上的一种实现,能够让用户把输入的DataFrame作为一张表,编写SQL处理输入的DataFrame处理得到新的DataFrame。MFusion:和MMapper类似都是用于处理数据,但是MFusion必须有两个及以上的输入。例如SqlMFusion,它的功能和SqlMMapper类似,但是必须输入两张及以上的DataFrame。MSink:用于下沉数据(写入文件、消息队列等),拥有一个输入,没有输出。例如ConsoleMSink是MSink在Spark上一种实现,能够把输入的DataFrame输出在控制台上,常用于调试。
扩展
Metal提供了算子扩展能力,你需要按照如下步骤实现新的Metal子类,然后打包注册即可。
- 首先,根据算子输入、输出的数量来选择算子类型。例如,你需要实现拥有一个输入、一个输出的处理算子,那么你应该选择
MMapper作为算子的父类。 - 然后,实现一个
MMapper的子类。如果你的算子是封装的Spark SQL处理逻辑,那么你可以直接实现SparkMMapper的子类。 - 最后,你需要在你的工程中配置
metal-maven-plugin或者直接使用metal-maven-plugin命令行来生成注册清单manifest.json。向Metal提交注册清单即可完成注册。
数据流Spec
数据流处理结构和算子配置定义在数据流Spec。数据流Spec包括version、metals、edges、waitFor四个部分。
version:Spec的版本号。metals:定义了一组Metal,每个Metal定义中包含了Metal的类型、id、名称和其它算子配置信息。edges:定义了一组数据流向。每个edge包含了起止Metal的id。在eges可以建立一个数据流的DAG。waitFor:定义了MSink执行优先级的DAG。
如下是一个简单的数据流Spec示例,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
{
"version" : "1.0",
"metals" : [ {
"type" : "org.metal.backend.spark.extension.JsonFileMSource",
"id" : "00-00",
"name" : "source-00",
"props" : {
"schema" : "",
"path" : "src/test/resources/test.json"
}
}, {
"type" : "org.metal.backend.spark.extension.SqlMMapper",
"id" : "01-00",
"name" : "mapper-00",
"props" : {
"tableAlias" : "source",
"sql" : "select * from source where id != \"0001\""
}
}, {
"type" : "org.metal.backend.spark.extension.ConsoleMSink",
"id" : "02-00",
"name" : "sink-00",
"props" : {
"numRows" : 10
}
}, {
"type" : "org.metal.backend.spark.extension.ConsoleMSink",
"id" : "02-01",
"name" : "sink-01",
"props" : {
"numRows" : 10
}
} ],
"edges" : [ {
"left" : "00-00",
"right" : "01-00"
}, {
"left" : "01-00",
"right" : "02-00"
}, {
"left" : "00-00",
"right" : "02-01"
} ],
"waitFor" : [ {
"left" : "02-00",
"right" : "02-01"
} ]
}

在示例中,source-00会从src/test/resources/test.json获取JSON数据,mapper-00将source-00作为输入并且筛选出id != "0001"的记录,sink-00将mapper-00过滤出的数据打印在控制台。sink-00会直接将source-00的数据打印在控制台。sink-00会先于sink-01被调度执行。
metal-backend
接口设计
metal-backend定义了metal的几种操作接口(analyse、schema、heart、status、exec等),并且实现了命令行模式和交互模式。
在交互模式下,metal-backend进程会启动REST服务和Vert.x RPC与metal-server通信。关于这几个接口,要做一些说明,
analyse: 接收数据流Spec,检查规范性。然后将Spec构建成Spark DataFrame组成的DAG。为了优化性能,Spec中没有发生变化的处理算子会直接复用。这些变化包括算子配置的变化、输入的变化(算子名称的变化不会影响复用)。schema:获取算子输出DataFrame的模式。Metal中统一用Arrow Schema表示。exec:执行基于Spec构建的DAG。heart:发送心跳。status:访问服务状态。
交互模型下,metal-backend要处理并发请求,上述接口操作大部分是可以并发访问的,一部分只能串行访问。heart、可以并发访问,analyse、schema、status和exec需要做并发控制。并发控制关系如下,
| analyse | schema | status | exec | |
|---|---|---|---|---|
| [prev] analyse | 不并发 | 不并发 | 不并发 | ==不并发== |
| [prev] schema | 不并发 | 并发 | 并发 | 并发 |
| [prev] status | 不并发 | 并发 | 并发 | 并发 |
| [prev] exec | 不并发 | 并发 | 并发 | 不并发 |
第1行第4列<analyse, exec>为不并发,这表示当analyse执行时,exec请求会被阻塞等待执行或直接方法。metal-backend定了IBackendAPI实现了这种并发控制,具体的设计图如下。

IBackendTryAPI中定义的接口为非阻塞接口。
运行模式
命令行模式
metal-backend实现了命令行模式,你可在spark-submit提交任务时配置数据流。例如,
1
2
3
4
5
6
7
8
9
10
$SPARK_HOME/bin/spark-submit \
--class org.metal.backend.BackendLauncher \
--master spark://STANDALONE_MASTER_HOST:PORT \
--jars $METAL_JARS \
--conf spark.executor.userClassPathFirst=true \
--conf spark.driver.userClassPathFirst=true \
$METAL/metal-backend-1.0-SNAPSHOT.jar \
--conf appName=Test \
--cmd-mode \
--spec-file $METAL_SPEC/spec.json
--cmd-mode表示开启命令行模式。 --spec-file表示定义的数据流Spec的URI,该URI需要Spark driver能够访问到。另外,你也可以使用--spec,在命令行中直接配置嵌入Spec的内容,例如,
1
2
3
4
5
$SPARK_HOME/bin/spark-submit \
...
$METAL/metal-backend-1.0-SNAPSHOT.jar \
...
--spec "{'version':'1.0', 'metals':[...], 'edges':[...], 'waitFor':[...]}"
数据流Spec中使用的算子所属的Jar文件也需要指明,你可将Jar文件的路径配置在--jars。
目前,metal-backend仅在Spark Standalone集群中测试过,Yarn和K8S还未进行过验证。
交互模式
metal-backend实现了交互模式,当开了交互模式,metal-backend会启动REST服务和Vert.x RPC服务。例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
./spark-submit \
--class org.metal.backend.BackendLauncher \
--master spark://STANDALONE_MASTER_HOST:PORT \
--jars $METAL_JAR \
--conf spark.executor.userClassPathFirst=true \
--conf spark.driver.userClassPathFirst=true \
$METAL/metal-backend-1.0-SNAPSHOT.jar \
--conf appName=Test \
--interactive-mode \
--deploy-id 35c0dbd3-0700-493f-a071-343bc0300bc9 \
--deploy-epoch 0 \
--report-service-address report.metal.org \
--rest-api-port 18000
--interactive-mode表示开启交互模式。--deploy-id为部署id,--deploy-epoch为部署纪元。部署id用于和metal-server通信,它能够关联到metal-server的一个Project;部署纪元则是为了提供了高可用而设计的,在metal-server为Project部署Backend时,会下发类似于上述示例的命令,来启动一个开启交互模式的metal-backend,为了防止网络异常或启动异常带来的影响,每次为同一个Project部署Backend时,部署纪元都会增加。--report-service-address是metal-server提供的追踪Backend状态的RPC服务地址。--rest-api-port是metal-backend启动的REST API端口。
除了开发调试时,几乎不会手动编写交互模式的命令,正常情况下是metal-server根据你的Project配置来自动下发部署Backend。
metal-server和metal-ui
metal-server
模型

metal-server建立了Project的概念来管理数据流以及相关配置。你可以在Project中选择需要的Metal算子,并且定义数据流。metal-server会根据配置部署执行后端,下发执行数据流,跟踪后端状态和数据流执行状态。
服务
metal-server实现了Vert.x RPC和REST-API服务。
- Report服务:用于接收
metal-backend上报的后端状态和任务执行状态。 - Failure Detector服务:追踪后端故障的检测服务,会将超时离线、进程关闭、延时过高的执行后端做下线处理。
- REST-API服务:为
metal-ui提供的服务,包括创建Project、配置Project、保存数据流Spec、部署后端、执行数据流以及追踪后端状态等。
metal-ui
metal-ui实现了Metal的前端Web UI。你可以在metal-ui中便捷地创建Project,选择算子包,绘制数据流,检查数据流,提交执行数据流,发布新的处理算子包,管理算子包等。
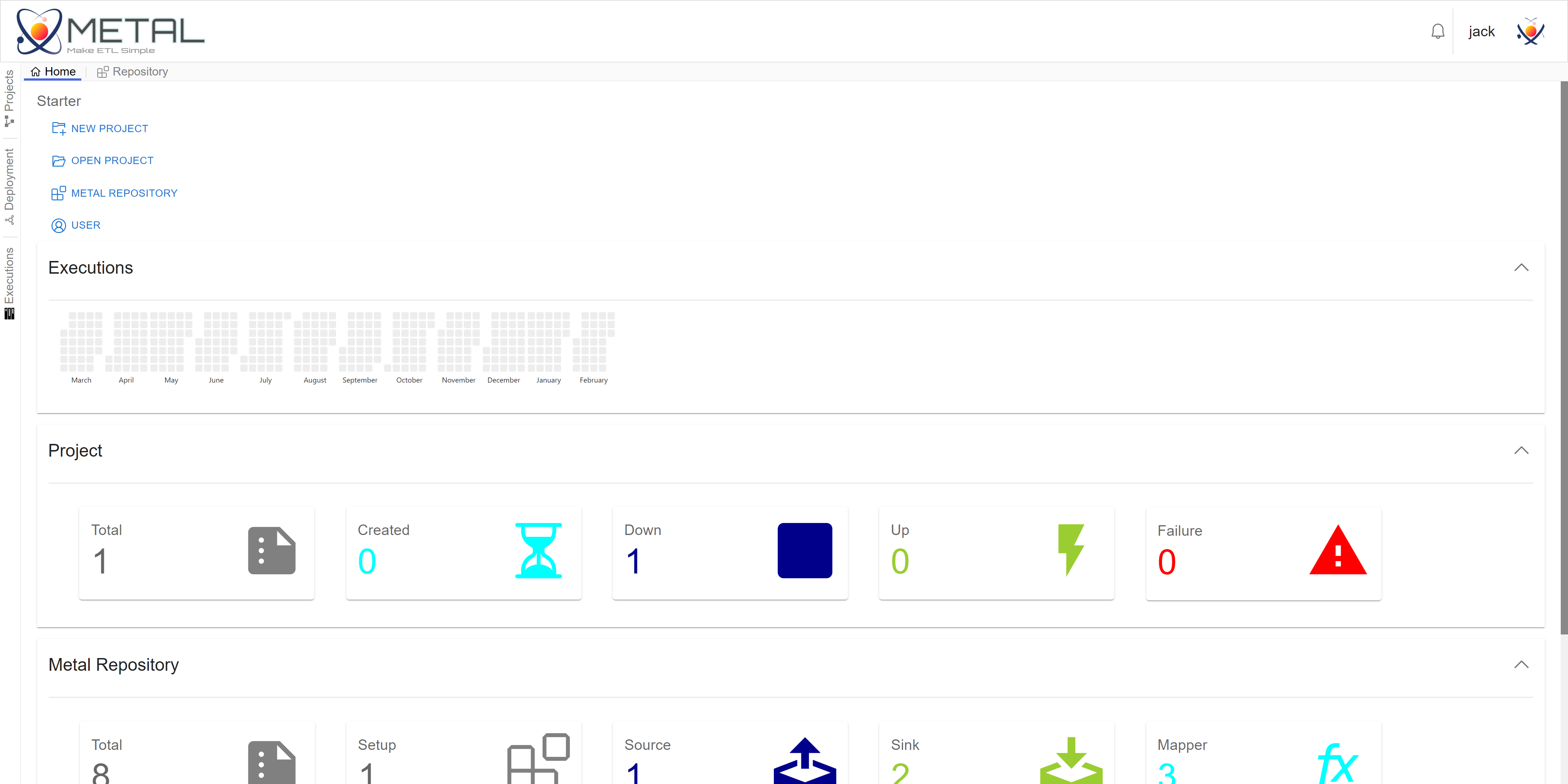
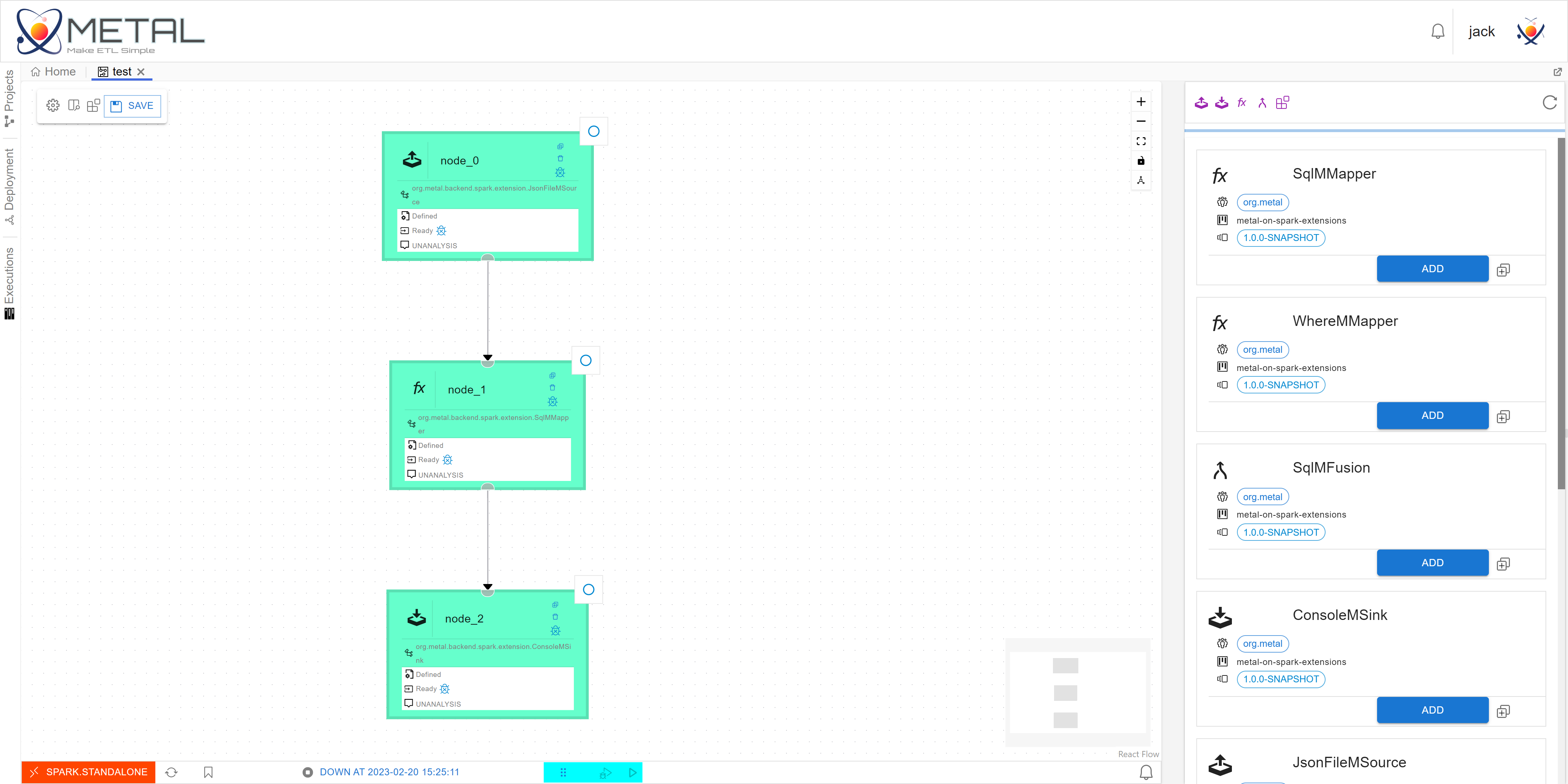
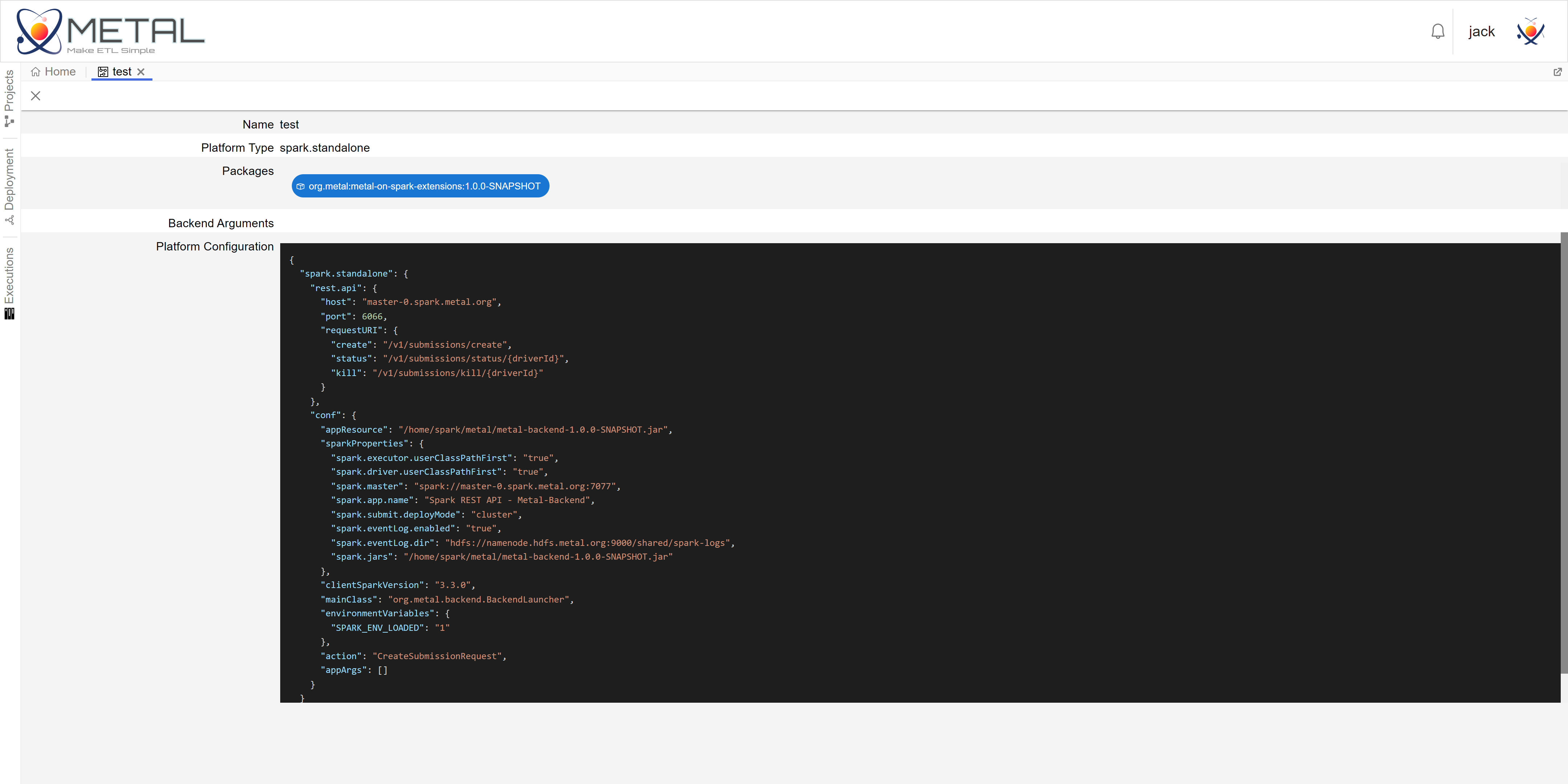
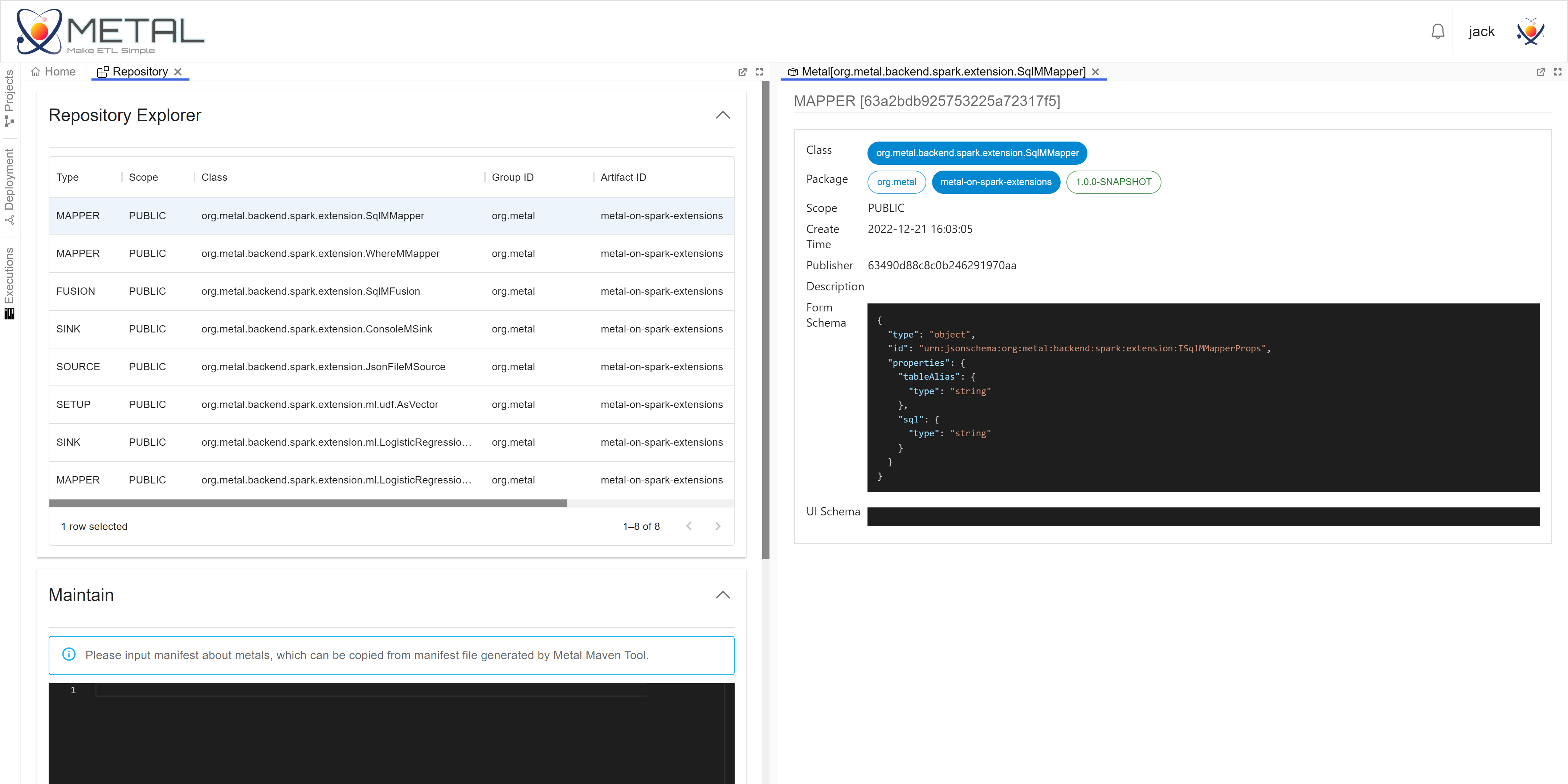
metal-ui是一个简易的数据流IDE,metal-ui会调用metal-server提供的REST-API完成操作
Open Source Plan
Metal项目仍处于开发,前文所展现的功能都已经完成。目前,Metal正式开源前还有如下问题需要解决:
- 合适的开源协议。会从GNU General Public License、Apache License或MIT做选择,暂时我本人更倾向于APL。
- 完善的文档。Metal的文档编写处于起步阶段,许多关键性的设计细节还没有被组织进文档。
- 有效的测试。我为Metal编写测试仅仅包括几个单元测试,还有大量的测试工作要做。
- 丰富的算子库。Metal项目只包括Json读取、SQL、线性回归和控制台输出有关的几个算子,能够作为生产力工具的算子还需要继续开发。
上述问题得到妥善处理后,Metal项目将会及时开源。